Transactional Information Systems 第11章 演習問題解答
Transactional Information Systemsにおける第11章演習問題の自分なりの解答。
間違っていたらご指摘ください。
11.1 Q
と
について、
と、対応する削減済みのスケジュールは?
11.1 A
アボートを時系列逆順の逆操作+コミットに置き換える。
隣接した逆操作どうしを相殺すると
11.2 Q
各スケジュールのRC,ST,RG,PRED,LRC性を判定せよ。
11.2 A
s1は、t1が書き込んだデータが終了時まで読み込まれないのでST、ゆえに自明にRCでもある。一方、t2が読み込んだデータが終了前にt1に変更されているのでRGではない。RCかつ、writeが一つしかないので自明にLRCであり、LRCかつCSRであることからPREDでもある。
よって
s2は、t1が書き込んだaにt1の終了前にt2が書き込んでいるのでSTでない。一方、reads-from関係がないので自明にRCである。また、 なのに
なのでLRCでなく、したがってPREDでもない。
よって
incr(a)はr(a)w(a)に相当する。なのでs3は、t2の書き込んだbを読んでいるt3がコミットしているのにt2がアボートしていることになり、RCでない。RCじゃないのでLRCでもなく、したがってPREDでもない。
よって
11.3 Q
各スケジュールのRC,ACA,ST性を判定せよ。
11.3 A
s1は、t1が書き込んだxがt2に読み込まれるのがt1のコミット後なのでSTである。
s2は、t1が書き込んだxをt2が読み込んでいて、 を満たしているのでRCである。一方、読み込みがt1のコミット前に行われているのでACAではない。
s3は、t1が書き込んだxをt2が読み込んでいるのに なのでRCでない。
11.4 Q
RC,ACA,ST,RG,PREDはそれぞれprefix commit closedか?
※スケジュールクラス がprefix commit closed:
ならば、そのうちコミットされたトランザクションのみを抜き出したコミット射影の任意のプレフィクス
が
を満たすこと。
11.4 A
RCはprefix commit closedである。
のコミット射影のプレフィクス
を考える。
において
という関係があるとき、コミット射影であることからプレフィクスを取る前は
も含まれていたはずである。したがって、以下の2つのケースに分けられる。
のケース。少なくとも
までのプレフィクスは
に残されているので
も
- もとのスケジュール
のreads-from関係が異なるケース。この場合、あるコミットされていないトランザクション
による書き込みが挟まり
のようになるが、これは
が
ACAはprefix commit closedである。
のコミット射影のプレフィクス
を考える。
において
という関係があったとき、
- もとの
への書き込みがない場合、
のACA性から
となって
。
- もとの
となる場合、
STはprefix commit closedである。
において
という関係があったとき、もとの
でも全く同じ関係があるので、
のST性より
である。
RGはprefix commit closedである。
STと全く同様。 STとRGはreads-from関係じゃなく単に衝突を問題にするので簡単。
PREDはprefix commit closedである。
PREDの性質より、 の任意のプレフィクスがreducible(可換操作と逆操作の相殺の末に逐次的なスケジュールにできる)である。
よって、そのコミット射影を取り出しても、やはりコミットされていないトランザクションが消えるだけなので明らかにreducibleである。
11.5 Q
証明せよ。
11.5 A
1. 
2. 
3. 
4. 
5. 
11.6 Q
任意のプレフィクスがXCSRであるようなクラスPXCSRについて以下を示せ。
11.6 A
1. 
2. 
3. 
まず 。
次に、 を考える。競合する操作が実行されたとき、その時点で前者のトランザクションが終了している。よって、トランザクションの終了順と競合する操作の実行順が同じであり、conflict graphは閉路を持たない。よって
であり、RGがprefix closedであることと合わせて
。
4. 
は自明である。
まず を示す。ST性に反する
もしくは
があったと仮定すると、
を含まないプレフィクスの拡張スケジュールが
という競合の閉路を引き起こすため矛盾。
次に、 が
に属することを示す。
の プレフィクス
がXCSRでないと仮定すると、もとの
でコミットだったものがプレフィクスに含まれなかったためにアボートになったことが原因になっている。そのような競合サイクルは
という形であり、これはST性(書き込まれたアイテムは、トランザクションの終了時まで読み込み/書き込みされない)に反する。よって
。
11.7 Q
を示せ。
11.7 A
SS2PLの性質から、一度書き込み・読み込みされたアイテムにはトランザクションの終了時までロックが保持され続けるので、それとロックが競合するような操作はトランザクションの終了後に初めて実行される。したがって である。
一方、RGであるようなスケジュールをSS2PLスケジューラに入力すると、トランザクション終了時まで競合する操作が行われないという性質が満たされているのでロックの競合によるブロッキングが発生せず、素通しになる。よって である。
11.8, 11.9
略
11.10 Q
全ての更新がトランザクション固有の空間で行われ、グローバルなデータへの反映がコミット時まで遅延される実装を考える。
ST, PRED, LRCの概念をこのような実装に応用できるか?それに意義はあるか?
11.10 A
コミット時に変更が一気に反映されるので、例えば を読みつつ変更を加えたトランザクションは
のように表記できる。ここで
は
への書き込みとコミットを不可分に行う操作となっている。アボート時にはこの
のような操作が現れず、変更が一切関知されない。=アボートしたトランザクションは存在していないのと同義。
コミット時点で変更が反映されるモデルにおいては、STはそもそも自動的に達成される(トランザクションの終了タイミングと書き込みの反映タイミングが同一)ので意味を持たない。
また、定義を考えてみるとLRCも意味を持たない。
PREDに関しては、まずこのケースでは元のスケジュールがREDであればプレフィクスがすべてREDなので、PREDとREDが等価である。またREDとCSRが等価である。よってPRED=CSR。LRCが意味を持たないこともこれの裏付けになっている。
Transactional Information Systems 第10章・第12章 演習問題解答
Transactional Information Systemsにおける第10章・第12章演習問題の自分なりの解答。どちらも短いので1エントリに統合。
間違っていたらご指摘ください。
10.1
Q
多重粒度ロックにおいて、lock escalationがデッドロックを引き起こすケース、引き起こさないケース
A
テーブルa1内にレコードr1,r2が、テーブルa2内にr3,r4がある状況を考える。トランザクションt1がr1,r3にwrite lockをかけ、t2がr2,r4にwrite lockをかけているとき、t1がr1のロックをa1全体に、t2がr4のロックをa2全体に昇格しようとすると、お互いにレコードレベルのロックの解放待ちになってデッドロックが起こる。
例えばこれがどちらもa1のロック昇格を望むだけなら一方がブロックされるだけなのでデッドロックにならない。
このようなデッドロックは、read/writeもしくはwrite/writeロックの競合時に起きるものなので、どちらも読み込みならば昇格も問題なく行われデッドロックは発生しない。
10.2
Q
lock de-escalation(escalationの逆、ロック粒度を細かくすること)が意味をなす例は?
A
- ロックの粒度を細かくする=ロックを一部解放してしまうため、2PLのうち後半の解放フェーズに使わないと安全でない。
- 長いトランザクションの途中で、最初は表全体からデータを読み取り、その後に一部のレコードに対してのみ書き込みを行いたい場合が考えられるが、これは同様の機能がSIXロックモードで実現できるため意味が薄い。
- 結局よく分からなかった。SIXでいいような...?
10.3
Q
SQL標準における分離レベル(serializability, repeatable read, read committed, read uncommitted)の各クラスに属するスケジュールの例
A
:後述
(lost updateの原因)
repeatable read-serializabilityに入りうるのは、「phantom problemは起こすが他の問題は防ぐ」ようなスケジュール。phantom problemは述語指向のロックのような複雑なロックにおいて起こる問題なので、単純にページモデルでの例は挙げられない。
8章2節の内容を参照して、
: delete from emp where dep="Service" and pos="Manager"
: select name, pos, salary from emp where dep="Service"
こうすると、の最初のステップはService部門のManagerのレコードのみロックするため、その削除後の
のService部門列挙クエリはロックに引っかからず実行できてしまう。実行結果がManagerのいない名簿になってしまっており、phantom problemが起こっている。
10.4
Q
snapshot isolationを満たすスケジュールのうち、データの一貫性が破壊されるものの例
A
t1とt2のwrite setが互いに素でreadが最新のバージョンを読んでいるので、sはsnapshot isolationを満たしている。
一方、例えば初期値がで制約
があった場合、
と
がそれぞれ$x,y$から10ずつ引いてしまうことがありえる。この場合、制約を満たさなくなっておりデータの一貫性が破壊されている。
よってsnapshot isolationは正当性の面で問題を抱える。
10.5
Q
snapshot isolationを保証する同時実行制御アルゴリズム
A
各データアイテムについて、コミットされたバージョンと最新のバージョンのタイムスタンプを保持する。読み込み時にはコミットされたバージョンを読み込み、書き込みでは、書き込みたいデータアイテムの最新バージョンタイムスタンプがそのトランザクション開始タイムスタンプよりも新しいときに不正状態なのでアボートする。コミット段階で書き込んだ最新バージョンをコミットされたバージョンに変換する。
10.6
Q
MVSRとsnapshot isolationはお互いを包含しないこと
A
12.1
Q
データベースキャッシュとログバッファが非揮発性・予備電源持ちのRAMに保存されているとき、障害回復が必要になるのはどのような障害の発生時か。
A
OSやDBMS、システムソフトウェアのエラーに起因する障害。
12.2
Q
非揮発RAMに加え、仮想メモリのページ保護機能により、通常動作中のソフトウェアによるメモリアクセスが注意深く管理されていたとき、ソフトウェアエラーに起因する障害に際していえることは?
A
- undoステップは必要である。クラッシュ時にアクティブだったトランザクションのロールバックが必要なのは非揮発でも変わらない。
- redoステップは必要ない。クラッシュ時点までの変更は全て非揮発RAMに反映されて残っている。
- データベースキャッシュのページが通常動作中に永続データベースに書き出されたとき、ログバッファを必ずしも書き出す必要はない。
- データベースキャッシュのページが回復による再開中に永続データベースに書き出されたとき、ログバッファを書き出す必要がある。再開中なのでメモリアクセスへの管理がされておらず、RAMの内容がエラーで破壊される可能性がある。
- トランザクションがコミットされたとき、ログバッファを必ずしも書き出す必要はない。コミットされたことを示すログエントリは非揮発RAMに反映されて残る。
Transactional Information Systems 第9章 演習問題解答
Transactional Information Systemsにおける第9章演習問題の自分なりの解答。
間違っていたらご指摘ください。
9.1
Q
インクリメンタルなキー範囲ロックは、ユニーク制約を持つインデックスに対してはどう変更されるか?
A
基本のインクリメンタルキー範囲ロックは変更なくユニーク制約インデックスにも適用できる。Insertどうしが競合するようにすればよい。
instant duration lockとinsert lockを用いた最適化を適用する場合は、insert lockどうしが競合するように設定する。唯一値しか許容されないため、競合が検出された時点でそのinsertは諦める。
9.2
Q
インデックスに存在する最小のキーよりもさらに小さいキーの検索にはどのようにロックを取得すればよいか、またそのようなキーのInsertとのロック競合をどのように保証するか?
A
インデックス内の最小のキーよりもさらに小さいキーをinsertしたいとき、このままだと直前の葉が存在せず、適切なロックができない。
従って、どの値よりも小さい最小の葉を番兵として最初から配置しておくことにする。こうすればInsert時にもSearch時にもその葉へのロックが要求されるため、正しく競合が検出される。
9.3
Q
存在していないキーのInsertどうしは競合してブロックを生じうるが(例:27も28もインデックスにないとき、先のInsert(27)は後のInsert(28)をブロックする)、本来可換なはず。この競合を避けるための方法はあるか?
類似する状況におけるDelete/DeleteどうしやInsert/Deleteについては?
A
Insertの際、挿入するキーにinsert lockを、直前のキーにinstant duration lockをかけることにする。 また、Deleteの際には、削除したいキーのみにwrite lockをかけることにする。
- 直前のキーへのinstant duration lockは一瞬しかロックをかけないので、2つのInsert操作の間にブロックは起こらない。
- Deleteは削除するキーにしかロックをかけないので、異なるキーの削除は互いに競合しない。
- Insert-Deleteについても、全く同じ理由で互いに競合しない。
9.4
Q
ユニーク制約のあるインデックスでのInsert時に、キーが既に存在して失敗する場合のロックの要件は?
A
insert lockどうしが競合するように設定し、insert lockどうしの競合が検出された時点で失敗と判定する。
9.5
Q
直前のキーでなく、直後のキーへのロックを考えた場合のロック規則はどうなる?
A
- search(x)は、xがインデックスに存在すればxに対するread lockを要求する。なければ、xより大きい中で最小のキーに対するread lockを要求する。
- next(currentkey,currentpage,highkey)はcurrentkeyの直後のキーに対するread lockを要求する。
- insert(y,RID)は、yとyより大きい中で最小のキーに対するwrite lockを要求する。
- delete(y,RID)は、yとyより大きい中で最小のキーに対するwrite lockを要求する。
9.6
Q
図を用いた問題なので問題文略。
A
アクセスレイヤでのロック手順を最初に答える。
はじめに11の直前のキー9にread lockをかけ、9→12→13→15→16→17→20→22→24という順に進む。 次にInsertの際には、27の直前である24のロックがwrite lockに昇格される。
次にページレイヤを考える。
根からr→p1→q3とread lockを順にかけ、順次親のロックを解放しながら下りていく。q3が終わったらq4へ、次にq5へ、最後にq6の最小キーが25より大きいことを確認して範囲検索は終了する。 次にInsertの際には、r→p2→q6という順にwrite lockをかけ、順次親のロックを解放しながら下りていく(全部split-safeなので開放しても問題ない)。q6はwrite lockに昇格される。
9.7
Q
B+木において、pがsplit-safeでないが、その子孫qがsplit-safeであるケースを考える。pもqもあるInsert操作のパス上に含まれていた時、lock couplingテクニックでは、ロック競合を最小化するため、ロックをどう取り扱えばよいか?
A
ノード分割は、split-safeでない親に向かって伝播していくが、split-safeなノードが一つ挟まった時点で伝播は止まる。したがって、qの子孫でノード分割が起きたとして、その影響はq以下にしか及ばない。よって、qへのロックを獲得した時点で、qよりも上のノードは全てロックを解放しても問題ない。もちろん、そのようなsplit-safeなノードに出会うまではpのロックは保持しておく必要がある。
9.8
Q
link techniqueのロック獲得規則をフォーマルに記述せよ。
A
link techniqueの前身となるlock coupling techniqueのロック獲得規則は以下であった。
- searchとrange_searchは、ノードにアクセスする際、そのノードへのread lockを必要とする。insertはwrite lockを必要とする。
- search, insert, およびrange_search冒頭の根から葉への降下において、ノードへのロックが許可されるのは、そのノードがフリーかつ、そのノードの親のロックを保有している場合のみである。
- searchは、子へのロックを獲得したとき、親のロックを解放してもよい。
- insertは、(a)子へのロックを獲得し、(b)そのノードがsplit-safe(キーをもう一つ足しても分割が起こらない) なときのみ、そのノードへのロックを解放してもよい。
- range_searchが葉ノードへのロックを許可されるのは、その親ノードか直前の葉へのロックを保持している場合のみである。前者は冒頭の根から葉の降下に、後者はnext操作による葉の連鎖に関連する。
- next(currentkey, currentpage, highkey)はcurrentpageへのread lockを必要とし、直前の葉へのread lockを保持している場合に許可される。
searchやrange_searchはノード分割が並列に起きても問題なく実行されるという観察を踏まえた最適化がlink techniqueであり、以下のようになる。
- searchとrange_searchは、ノードにアクセスする際、そのノードへのread lockを必要とする。insertはwrite lockを必要とする。
- insertにおいてノードへのロックが許可されるのは、そのノードがフリーかつ、そのノードの親のロックを保有している場合のみである。
- searchは、子へのロックを獲得したとき、親のロックを解放してもよい。
- insertは、(a)子へのロックを獲得し、(b)そのノードがsplit-safe(キーをもう一つ足しても分割が起こらない) なときのみ、そのノードへのロックを解放してもよい。
- next(currentkey, currentpage, highkey)はcurrentpageへのread lockを必要とする。
9.9
Q
B+木の葉ノードが双方向に接続されている状況を考える。これはキーを降順に範囲検索するのに便利。
このとき、ページレベルのlock couplingやlink techniqueはどのような影響を受ける/変更されるか?
A
まず、link techniqueは葉のリンクが昇順にしか辿られず、新しいノードも同じ方向にしか作られないという性質に基づいた最適化なので、双方向のリンクがある場合には適用できない。
次にlock couplingであるが、
【読書メモ5-2】Transactional Information Systemsを読み終わった
前回
ノート
はじめに
集中して読む時間を取れたおかげでようやくTransactional Information Systemsをすべて読み終わった。
前回に引き続き、全体的な感想と各章の個別の所感を書き残していきたい。
全体的な感想
トランザクションのACID特性を達成するための理論的なベースと様々に試みられてきた工夫を概観し、全体的な地図を頭に入れることができたという感触がある。
読む前も「ACID特性とは何か」といった問いには答えられる程度ではあったが、読み終わった今ではそれに対する解像度が全く異なっている。トランザクションの分離性をどのような同時実行制御アルゴリズムで担保するのか、不可分性をどのような回復アルゴリズムによって実現するのか、I/Oコスト的に最適なバリアントは何か、といった深掘りした問いにも答えられるようになっている。ある程度咀嚼されて自分のものになっている感触がある。
2023年の今でもトランザクション制御に関する基礎理論の全体像を結ばせてくれるという価値は唯一無二である。興味を持った人にはぜひ読むのをおすすめしたい。
とはいえ非常に長かった。特に第三部は障害からの回復をメインに論じているため、実装的な観点からの解説が多く、それがあまり興味を惹かないのも効いた。非常に長い英文を追い続けた結果、読む速度はそれほど変わっていないが耐性は多少強化された気がする。
章別感想
第3部
第11章 トランザクションの復元
第2部までで考えてきた同時実行制御は、各トランザクションが成功することを前提としていた。第3部で初めて、トランザクションが失敗しても安全にロールバックできるかどうか、に関する正当性が複数導入される。
与えられたスケジュールに関する判定の基準として
- XCSR:ロールバックに関連する操作で拡張したスケジュールがCSRかどうか、という基準。
- PRED:スケジュールの任意のプレフィクスがreducibleかどうか(可換性に基づいて操作を並び替え、逆操作を相殺していったときに逐次的にできるか)、という基準。
次に、生成するスケジュールに課す条件として
- RC (Recoverability):トランザクションAからデータを読んだトランザクションBは、Aがコミットされるまでコミットされない。
- ACA (Avoiding Cascading Aborts):コミットされたデータしか読み込めない。
- ST (Strict):トランザクションが終了するまで、それが書き込んだデータアイテムが読み書きされることがない。
- RG (Rigorous):STに加え、トランザクションが終了するまで、それが読み込んだデータアイテムが書き込まれることがない。
- LRC (Log Recoverability):RCかつ、write-write conflictの実行順に制限をかける。
これらの間の関係も導出される。例えば、とか、
とか。
3章の面白さが再燃してとても楽しい章だった。
第12章 障害回復に関する正当性
スケジュールがCSRかつLRCを満たすことを前提としたうえで、データベースが障害を起こしてメモリのデータが揮発したさい、安全に元の状態に復帰するための障害回復アルゴリズムを考えていく。本章はそのとっかかりとしてデータベースやログをフォーマルに定義し、障害回復アルゴリズムの全体像を概観する。
ログって、これまでは単なるデバッグ用の情報を記録するものという感覚だった。が、どうやらデータベース・トランザクションという分野ではそんなふわっとしたものではなく、障害回復を正しく行うための必須コンポーネントであるということを知り、ギャップが埋まった。
第13章 ページモデルにおける障害回復アルゴリズム
トランザクションの実行に関連する情報はログに記録していき、トランザクションのコミット時などのタイミングでログバッファをストレージに書き出す。
障害回復はこのログのスキャンを3回することで実現する。
- analysis pass:ログを読んで、コミットに失敗したトランザクションのリストを得る。
- redo pass:コミットされたトランザクションの内容をデータベースに反映しなおす。
- undo pass:失敗したトランザクションの内容をデータベースから取り除く。
さらに、I/Oコストやログサイズを最適化するために、チェックポイントやログ切り捨てといった手法が導入される。
データベースがキャッシュからストレージに書き出される際のI/Oコストが大きいせいで種々の工夫が必要になっているので、大容量安価なストレージがHDDからSSDに世代交代してI/Oが高速になったらもう少し違ったアルゴリズムが有用になるのかもしれない。
第14章 オブジェクトモデルにおける障害回復アルゴリズム
第13章の内容をオブジェクトモデルに拡張する。
第15章 障害回復における諸問題
12-14章で触りきれなかった雑多な話題。
第16章 メディアの回復
メモリの揮発だけでなく、ストレージそのものが故障や火災で吹っ飛んでしまった場合の対策を考える。
2つの手法を併用する。
- バックアップベースの手法。別ストレージに定期的なバックアップとログのコピーをとっておき、これをもとに復帰する。
- 誤り訂正符号ベースの手法。パリティを分散配置することで、1つのストレージが故障してもそのデータを符号から復元できる。RAIDで実用化されている。
章の冒頭でさすがに周辺のデータセンターをまとめて巻き込む大規模災害は無理、みたいなことを断ってて、あまりに厳密な誠実さに少し笑った。
第17章 アプリケーションの回復
クライアント―サーバ型アプリケーションのような、対話的なトランザクションの回復を取り扱う。主題になるのは、ストレージに保存することで耐障害性を持たせたメッセージキューを利用したメッセージのやり取りである。
著者曰く、近年のeコマースなどで広く用いられるクッキー/URLを用いたセッション管理は「対話的なトランザクションを再発明したものであるが、悲しいことにトランザクション的でない=ACID特性を満たせないクッキー/URLに頼ってしまっているのが皮肉だ」とのこと。次世代のeコマースシステムはトランザクション的な高信頼手法を採用すると信じている、と書いているが、現在でもステートレスなHTTPとクッキー/URLを用いたアーキテクチャが一般的なことを見ると著者の予測は外れているだろうか。
第4部
第18章 分散トランザクションの同時実行制御
分散システムにはホモジニアスなものとヘテロジニアスなものが存在する。
ホモジニアスなものは、複数のサーバを論理的には単一のユニットとして取り扱うもので、2相ロックによって普通に制御できる。ただし、ロックの取得フェーズから解放フェーズに移行するタイミングをサーバ間で同期しなければならない。
ヘテロジニアスなものは、サーバ間をまたがるグローバルなトランザクションに加え、単一のサーバで実行されるローカルなトランザクションも許容したシステムであり、これによる難しさが追加で発生する。
分散システムってやたら難しそうと身構えていたが、意外とここまでの概念の拡張でいけるものである。
第19章 分散トランザクションの回復
分散システムの回復を行ううえで重要なのは、トランザクションがコミットされたのかアボートされたのかの判断をサーバ間で統一すること。これを2相コミットプロトコル(2PC)を用いて実現する。
具体的には、サーバの中からコーディネータを1つ定め、コミットの開始時に、関わる全サーバにコミット準備を要求する。全てのサーバが準備完了のメッセージを返信してきたらコーディネータはコミットを命令する。一つでも準備ができなかったならアボートを命令する。
2相コミット、聞いたことはあったがこの文脈にあったのかと目から鱗だった。
第5部
第20章 展望
本書の振り返りや将来的な課題について述べられているが、特に印象的なのはデータレプリケーションの話題。
ユーザが世界中に散らばっているインターネットアプリケーションのような状況では、各地域からのアクセスを高速にするため、同一のデータアイテムの複製を各所に配置するような必要が出てくる。それらデータの一貫性を維持するためのreplication control(複製制御)について触れられている。これは今になってさらに重要性を増している話題なので、より最新の文献をあたって見るのも面白そう。
おわりに
せっかく大著をここまで噛み砕きながら読み切ったので、演習問題にもしっかりと答えを出していきたいし、できればここに解答エントリを載せたい。
あとは、現代のSQL標準や、オープンソースRDBMSがどんな発展を遂げていて、どのアルゴリズムが採用されているのかをリサーチしていきたいところ。
【読書メモ5-1】Transactional Information Systemsを読んでいる
はじめに
修論なりで更新が滞っていたので、読み途中ではあるがTransactional Information Systemsの読書メモを書いておくことにする。
英語で700P超えの大著なので読むのには気力がいる。そしてkindle版でも1万超えという専門書の風格。
日本語でまとめた資料をHackMDで作りながら読んでいるので、原著を読むのがしんどいという方に参照していただければ幸いである。
全体的な感想
『データベース実践入門』でおすすめされていたので気になって読み始めたが、確かに面白い。
まず、この本はデータベース分野の中でもトランザクションについての話題だけを取り扱っている。いわゆるACID特性を満たすための、同時実行制御と障害回復アルゴリズムについて、それぞれ1部ずつ割いて丁寧に説明されている。
データベース分野で最も研究が進んできたトランザクションの概念を、データベースに限定しない一般的な概念として定義しなおしている。曰く、トランザクションとは本質的に、アプリケーションプログラムと複数のトランザクションサーバの間の契約で、複数のリクエストを単一の論理的な単位としてまとめて取り扱うためのもの、とのことである。また、最大の見どころは、複数のトランザクションの逐次実行可能性(serializability)に対する数学的に厳密な特徴づけを与えているところである。
どうしても最重要の応用先がDBMSなので、実装の詳細に踏み込んで語っている部分もある(特に後半の障害回復)が、前半部の逐次実行可能性の定式化なんかはよく抽象化されていて一般的な議論になっている。同値類なんて言葉をここで見られるとは予期していなかったのでなんだかうれしい。
現在読み終わっている第2部まで、各章の概要と感想を述べていくことにする。詳細な定義や定理なんかはHackMDを参照。
章別感想
第1部
第1章 概要
トランザクションについて考えていくにあたり背景となる項目について述べている。トランザクションが満たさなければならないACID特性であったり、DBMSに求められる性能要件であったり、DBMSの基本的な実装についてであったりがさらっと。
第2章 計算モデル
トランザクションについての定義を明確に与え、また複数のトランザクションの集合体であるスケジュール(DBMSのスケジューラに順次与えられるリクエストの列を抽象化したもの)についても定義している。ここで、2種類の計算モデル、「ページモデル」と「オブジェクトモデル」が定義される。
- ページモデル:ページのみが操作の対象となるデータであり、トランザクションが各ページpに対する読み込み
と書き込み
、コミット
、中断
のみからなるモデル。最も単純化されているが、だからこそかえって本質を掴むのに役立つ。
- オブジェクトモデル:ページに限らない、より抽象的なデータオブジェクトへの操作を許したモデル。あるデータオブジェクトへの操作が、実質的には複数のページへの操作を必要としたりするので、トランザクションは必然的に木構造をとることになる。トランザクションが単なる操作列であるページモデルと、そこが大きく異なる。
この本では基本的に、ページモデルについての性質を述べ、それをオブジェクトモデルに一般化する、という形で議論が進む。実際、オブジェクトモデルに一般化する際にそれほど苦労を伴っていないので、まずページモデルで本質的な議論をするという試みが成功していることが分かる。
第2部
第3章 同時実行制御:ページモデルにおける正当性の定義
まず、複数のトランザクションからリクエストが送られてきたとき、それを愚直に到着順のまま実行するといろいろな問題が起きる。例えば以下。
- lost update
- inconsistent read
- dirty read
したがって、トランザクションを並列実行するにあたって、スケジュールをどの順番で実行するのか決定するアルゴリズムを備えたスケジューラが必要になるわけである。まずこの章では、スケジューラに生成させたいゴール地点として、ある意味で「正当」なスケジュールの集合を定義している。スケジューラの具体的なアルゴリズムは4章以降で導入される。
では、スケジュールの「正当性」とはどう定義されるのだろうか?
根底にあるアイディアはこの2つ。
- 少なくとも、逐次実行するようなスケジュールは自明に正当といえる。例えば、トランザクションt1とt2とt3があったとして、t1を実行し、終わったらt2を実行、それが終わったら今度はt3、というように順番に行う場合、これは並列実行に起因する問題を一切引き起こさない。
- そのような逐次実行スケジュールと、なんらかの意味で等価なスケジュールもまた、正当といえるのではないか。
そこで、数学は集合論における同値類の概念を用いることにする。スケジュール全体の集合を考え、スケジュール間の同値性を定義し、逐次的なスケジュールと同値なスケジュール全体の集合を「正当」なスケジュールの集合として定義するわけである。
ここで、定義する同値性の種類に応じて、複数の正当性基準が誕生することになる。
他にも細かく定義されているが、とりあえずこの三者が最も代表的。これらのスケジュール集合は の関係を満たす。つまり、CSRが最も厳しい基準である。
lost updateもinconsistent readも防ぐにはCSRが必要(FSRやVSRでは力不足)で、またCSRは判定が容易という圧倒的な強みを持っているので、基本的にスケジューラはCSRを達成するように設計される。少し踏み込んで言うなら、スケジュールがFSR/VSRに属するかの判定はNP-hard、一方でCSRはトランザクションをノードとして作ったConflict Graphなるグラフの閉路存在判定によって容易に確かめられる。
第4章 同時実行制御アルゴリズム
第3章で導入された正当なスケジュールについて、それを達成するようなアルゴリズムについて記述されている。
まずはロックを用いたスケジューラ。つまり、データを操作するときにはそのデータにread/writeロックをかけ、かかっている間は他のトランザクションからの操作が禁止されるような機構を用いて同時実行制御を行うアルゴリズムである。 ロックを使う、というだけだと何も保証されない。大事なのは二相ロック(2 Phase Locking, 2PL)、つまりトランザクションが2つのフェーズに分けられ、前半のフェーズではロックの取得のみが許され、後半のフェーズではロックの解放のみが許されるというような性質が満たされたときに限り、生成されるスケジュールがCSRに属することが保証される。実用的には、トランザクションが終了する直前に全ロックを解放すれば簡単に2PL性を満たせることになる。
次にロックを用いないスケジューラ。紹介されているのはTimestamp Ordering(TO)、Serialization Graph Testing(SGT)、Backward-oriented Optimistic Concurrency Control(BOCC)、Forward-oriented Optimistic Concurrency Control(FOCC)の4つ。TOはトランザクションのタイムスタンプに応じて実行の可否を決めるもの。SGTはConflict Graphを保持しながら、その閉路判定を踏まえてCSR性を保証するもの。BOCCとFOCCは楽観的なプロトコルという分類に属し、トランザクションの内容はとりあえず全部実行するが、コミットの段階になってそれがコミットされてもいいか検証を行う。
最後にこれらを組み合わせたハイブリッドなスケジューラについてもさらっと。
第5章 マルチバージョン同時実行制御(MVCC)
ここまでで述べられてきた計算モデルにおいて、各データは唯一のものしか許されていなかった。例えば、ある時点において、ページ の内容はどのトランザクションから見ても全く同じであり、他のバージョンが存在するなどということは考えなかった。ここで制限を緩め、複数のバージョンが存在してもよく、過去のバージョンを読み込むこともできる、と仮定すると、もっといろいろなスケジュールが逐次実行可能になってくる。
そのような、マルチバージョンという状況下での逐次実行可能性、および同時実行制御アルゴリズムについて述べられているのが本章。
マルチバージョン的な意味でのVSRとCSRに相当するMVSR、MCSRというクラスが定義されるのだが、こちらの同時実行制御アルゴリズムではMCSRでなくMVSR性が保証されることが少し不思議である。また、VSRとMVSRの関係や、バージョン数を制限した場合に生じるクラス間の関係なども生じてきて、その辺のベン図を眺めているのがとても面白い。
第6章 オブジェクトモデルにおける逐次実行可能性
第3章におけるページモデルの逐次実行可能性を拡張し、オブジェクトモデルにおける正当性が定義される。
CSRは複数のトランザクション間で「競合」する操作(同じデータに対するread/writeまたはwrite/write)を定義し、それらの実行順を変えないまま逐次実行順に並び替えられるスケジュールのクラスであった。
それを拡張して、いわばオブジェクトモデルにおけるConflict Serializabilityに相当するTree Reducibilityが定義される。まずオブジェクトモデルにおける操作間の可換性を与える(ページモデルにおけるread/writeと異なり、独自定義の操作が許されているために可換性も自分で与えなければならない)。可換な操作の間でのみ実行順を入れ替え、他のトランザクションと切り離すことのできた部分木の枝刈りを許して木を変形していき、最終的にトランザクション群が逐次的に並び替えられたら正当、といった具合になる。
この章あたりは、ページモデルから簡単に導けるという口実の下にかなり端折られているので少し戸惑う。あと、モデルが複雑なので仕方ないのだが、導入される定義が結構複雑な言葉からなっていて理解に苦労する。
第7章 オブジェクトモデルにおける同時実行制御
まず、オブジェクトモデルスケジュールの中でも特殊ケースである「平坦」なスケジュールから始まり、次に「階層的」なスケジュールに対して、最後に一般のスケジュールに対しての同時実行制御アルゴリズムが導入される。
まず平坦なスケジュールとは、各トランザクションがレコード操作からなり、レコード操作がページ操作からなる、というような2層構造をしており、これはそれぞれの層に別個に2PLなどのアルゴリズムを使えば簡単に制御できる。
次に、層が増やされた階層的なロックについても基本的に各層にページモデル用のを適用するだけ。
最後に一般のスケジュールについては、階層的なものと違って、全ての操作が全ての層を経由するわけではないため、そういった抜けを管理するためにretained lockなる層をまたぐロックの概念を必要とする。それを除けば階層的なロックと同様である。
retained lockが実用においては重いため、スケジュールが階層的であることを要求した上で各層にページモデルスケジューラを適用するのが、商用システムにおける基本となっているようだ。
第8章 RDBMSにおける同時実行制御
RDBMSという特定の応用下での同時実行制御の話題を述べているが、個人的にさして興味深くないので割愛。ただ述語指向のロック制御の話は割と重要だと思う。
第9章 インデックスにおける同時実行制御
こちらもDBMSにおけるインデックスという特定のデータ構造でのロック制御について記述されているが、アルゴリズミックなのでなかなか面白い。
インデックスはB+木という木構造をしており、その構造特有の性質を活かして2PLよりも少し緩いアクセス制御を行っても許される。レコードレベルとページレベルのそれぞれのレベルにおけるロック制御法を紹介した上で、最適化の話もちょろっとされている。
第10章 実装における諸問題
ロック管理機構の具体的な実装法であったり、マルチバージョン制御の実装であったり、SQL標準におけるserializabilityの取り扱われ方だったり、負荷制御だったりという実際的な問題に関する雑多な話題。
おわりに
そろそろまた読書を再開できそうなので、第3部・第4部もしっかり読み終えたいところ。終わったらそちらもまとめるつもり。
情報系の人がゲノム配列データを扱いたいときの暗黙知【GRCh, VCF, etc...】
はじめに
私はアルゴリズム・データ構造系の人なのでバイオインフォマティクスには詳しくない。
だが、圧縮文字列索引の性能評価を行うにあたって、ヒトゲノム、特に1000 Genomes Project (以下1KG)から取得した大量の配列を連結した文字列としてのヒトゲノムには大きな魅力がある。
なぜなら、以下の条件を満たすため。
- 非常に巨大なデータで
- 反復が非常に多く(圧縮しやすい)
- indexingに実用的な意味がある
その一方で、いざ実物の塩基配列を取得してみよう!と思っても、バイオインフォマティクス界隈のファイル形式は独特であり、またどのように配列が推定されるのかというプロセスへの知識も必要になってきて面倒なのが実情である。
実際、自分が1KGのデータリポジトリを意気揚々と訪れたときには、謎の拡張子のファイルやとても塩基配列ではないようなファイルの羅列に圧倒された。結果的に、どれが何の役割を果たしているのか理解するのに結構な時間を要した。たぶん、バイオインフォマティクスの人としては常識・暗黙知の部類であり、わざわざ解説するまでもないことなのだろう。私としては全くそんなことはないので、逐一用語や拡張子をググりつつ極端に少ない日本語情報に辟易しながら英語Wikipediaをページ翻訳したりしていた。
現在ではふんわりと理解が進んだので、用語やデータ取得の過程について記録を残しておき、同様に困っている人への助けにしたい。ただし、あくまで情報系の人がデータを利用するためという観点からの説明であり、厳密ではないし、たぶん間違いはあるし、必要でないことにはまったく踏み込んでいないのに注意。
用語
GRCh38 / GRCh37 / hg38 / hg19
これらはヒトゲノムの「リファレンス配列」を指す言葉である。つまり、ヒトゲノムのお手本のようなもの。
まず人によってDNA配列には若干の差がある。したがって、「これがヒトゲノムだ!」という唯一の配列は存在しない。代わりに、集めた個体サンプルのデータを総合して「これがまあ、ヒトゲノムの見本として妥当だよね」ぐらいのノリで作られるのがリファレンス配列である。
だから、作り方 (サンプルの数、取ってくる地域、推定のやり方) によってリファレンス配列の内容は変わってくる。これが複数のリファレンス配列が存在する理由。これら一つ一つのリファレンス配列を「アセンブリ」とも呼ぶ。
- GRChはGenome Research Consortium humanの略で、その後に続く数字が世代らしい。つまり、GRCh38はGRCh37の後に作られたもの
- hgはhuman genomeの略で、GRCh38≒hg38、GRCh37≒hg19らしい。とりあえず今はGRCh38を使えばいい
VCF
ファイル形式の名前。hogehoge.vcf みたいなファイルがVCFを採用している。
Variant Call Formatの略であり、このファイルがやりたいことは
- いろんな個体のサンプル配列を1ファイルにまとめたい!
ということ。
リファレンス配列はいろんな個体のサンプルを元に作られるわけで、元となった大量の個体ごとのサンプルも遺伝子を解析するうえで大事。かといって、各個体の塩基配列全体を一つ一つ保存していてはあまりに冗長だし、データがデカくなりすぎる。
どうせ塩基の大半は同じなのだから、リファレンス配列を基準として、違う部分だけを指定してまとめたファイルを作れば手間が大幅に削減できる!という考えで生まれたのがVCFということになる。ファイルの中身は表形式のテキストファイルになっていて、各列が個体を、各行がリファレンス配列と異なる箇所とその内容を指している。
ここまでくると、リファレンス配列とVCFファイルさえあれば、サンプル個体の配列が全て生成できることが分かってくるだろう。
1KGの個体サンプルの情報が集まったVCFファイルは Index of /vol1/ftp/data_collections/1000_genomes_project/release にある。ここにはSNVとSNV_INDELという二種のVCFが置いてあるので、それらの違いも説明すると...
SNVとINDEL
塩基配列の変異の種類を指すワード。SNVは Single Nucleotide Variants 、つまり塩基一つが別のものに変わった変異。INDELは INsertion/DELetion 、つまり塩基が欠損したり余分なものが挿入されていたりする変異。(他にもCNVというのもあるそう)
SNVとSNV+INDELだったら、より考慮されている変異が多いSNV+INDELを使うのがたぶん良い。ぶっちゃけ文字列として取り扱うならどっちでもいいが。
exome (エクソーム)
ゲノムの中でも、タンパク質を合成するために必要な情報を持つ部分のこと。要はゲノムのサブセット(単に情報系の視点から見れば)。ゲノムをデータとして使う際は用がない。
データを取得した過程
ここまで分かればあとは割と早い。
取得する必要があるのは2つ。
- リファレンス配列。GRCh38なら Index of /vol1/ftp/technical/reference/GRCh38_reference_genome の GRCh38_full_analysis_set_plus_decoy_hla.fa がそれと思われる。ちゃんと3GBぐらいでヒトゲノム配列サイズになってるので安心。
- VCF。今回は1KGのSNV+INDELのVCFを使いたかったので Index of /vol1/ftp/data_collections/1000_genomes_project/release/20190312_biallelic_SNV_and_INDEL から取得。
これらから、サンプルに対応する配列を生成する。これには bcftools を用いる。セットアップ等は情報系の得意領域なので説明の必要はないと思う。 github.com
これはVCFファイルからいろんな操作をしてくれるプログラムで、bcftools consensusコマンドにリファレンス配列とVCF、生成したいサンプル名をぶち込めば、目的の配列が得られる。ようやくゴール。
私の場合はここから生成した配列を全部連結してデータセットに仕立て上げるわけである。長い旅だった。
【読書メモ4】Java言語で学ぶデザインパターン入門第3版
結城浩, 『Java言語で学ぶデザインパターン入門第3版』, SBクリエイティブ を読む。
C++と共通する部分があるとはいえJavaも個別に学んでおきたいのと、同時にデザインパターンも学べて一石二鳥なため。
本エントリでは概要と自作のUMLクラス図を配置して一覧性を高め、演習に使ったリポジトリを GitHub - U-Ar/design_pattern: 演習 of 『Java言語で学ぶデザインパターン入門第3版』 に置く。
デザインパターンに慣れる
1.Iterator

並んだアイテムに繰り返し処理を行いたいときに用いるパターン。
リストに相当するクラスはIterable
メリット
繰り返し操作が、実装の詳細に依存せずに行える。つまり、hasNextとnextというメソッドさえ持っていればよい。 配列の内部実装を変更しても、利用する側のコードに変更はない。
これはインタフェースが存在する意義といえるだろう。
2.Adapter

継承もしくは委譲を用いて、元のクラスの機能を必要な形に変換するパターン。
(継承の場合)
必要な機能を持つクラスを継承し、それと別に必要なインタフェースを実装する。
(委譲の場合)
Javaではクラスの継承は1つのみであることに注意(インタフェースは複数可能)。Targetがインタフェースでなくクラスで実装されていて継承-実装ができない場合、Adapteeはフィールドにインスタンス化してそれに実行を委譲、Targetのみ継承する、という形で実装する。
メリット
既存のコンポーネントを高速に再利用できる。後方互換性の維持にも役立つことがある。
サブクラスに任せる
3.Template Method

スーパークラスで処理の枠組みを定め、サブクラスでその具体的内容を定めるデザインパターン。
メリット
共通のロジックを一か所にまとめて記述できる。サブクラスの実装時には、スーパークラスとして取り扱っても可能な限り問題なく動作する必要があるのに注意。
4.Factory Method

Template Methodパターンをインスタンス生成の場面に適用したもの。インスタンスを生成する工場(Factory)のイメージ。生成に際して例えば製品の登録などの処理を組み込める。
を実装する。
他にもインスタンスを生成する静的メソッドをstatic Factory Methodと呼ぶことがある
メリット
newによる実際のインスタンス生成をインスタンス生成のためのメソッド呼び出しに変えることで、具体的なクラス名による束縛からスーパークラスを解放する
これによりnew Productの記述がなくなり、Productを抽象クラスのままにしておくことができる
インスタンスを作る
5.Singleton

インスタンスがただ一つしか存在しないことをプログラムで表現するためのパターン。
コンストラクタはprivateになっており、Singletonクラス外部からの生成を禁止している。
静的メンバにインスタンスを保持しておき、getInstanceではそのインスタンスを返すことで唯一性を保証する。
インスタンスは初めてのgetInstance呼び出し時に生成されることに注意。
enumの要素はインスタンスの唯一性が保証されているので、Singletonとして利用することができる。
6.Prototype

インスタンスを、クラス名を指定することなくコピー生成するためのパターン。
使うケースは主に
要は、java.lang.Cloneableインタフェースのcloneメソッドを使いたいが、cloneはprotectedで外部から使えないため、Cloneableを継承したクラスの別メソッドを経由するやり方。
注意点
- Cloneable自体にはcloneメソッドの宣言はなく、むしろjava.lang.Objectで定義されている。あくまでcloneをサポートしていることのマーカーインタフェースでしかない
- cloneは浅いコピー
- cloneを使うよりコピーコンストラクタやコピーファクトリを使う方が良いケースも多い
7.Builder

構造を持ったインスタンスを段階的に組み上げるためのパターン。
MainクラスはDirectorクラスのconstructメソッドだけを呼び出す。DirectorクラスはBuilderクラスのメソッドだけを使って構築する。それ以外の知識を持たないことによりコンポーネントが独立し交換可能性が高まる。 使われる具体的なクラスは後で指定できる(依存性の注入、Dependency Injection)。もちろん設計時に将来的に必要になるメソッドは十分に見通しておく必要がある。
8.Abstract Factory

インタフェースが定まっている抽象的な部品を組み合わせて複雑なインスタンスを組み上げるためのパターン。
Builderパターンは似ているが、段階を追って大きなインスタンスを作る感じ。
分けて考える
9.Bridge

機能を表すクラス階層と実装を表すクラス階層を分け、橋渡しをするためのパターン。
- 機能を表すクラス階層における継承の関係は
- スーパークラスは基本的な機能を持っている
- サブクラスで新しい機能を追加する
- 実装を表すクラス階層における継承の関係は
これらを明示的に弁別する。機能側クラスのフィールドとして実装クラスのインスタンスを保持し、実行を委譲する。
10.Strategy

使用するアルゴリズムを切り替え、同じ問題を別の方法で解くのを容易にするためのパターン。
以前C++で実装した自作の簡潔ビットベクトル( https://github.com/U-Ar/BV )にこのパターンを暗黙的に使っていた。配列全体を定数長のブロックに分割し、ブロック内で立っているビット数に応じて2種のサブクラスに場合分けを行って索引を構築する仕組みになっている。どちらのサブクラスでもrank, selectといったメンバ関数をオーバーライドしており、共通して実行することができる。
メリット
- 委譲という継承よりも緩やかな結合を利用しているので、アルゴリズムを容易に切り替えられる。ユーザとの対戦を行うプログラムなどで有効。
- 実行中に切り替えることも可能。
同一視
11.Composite

容器と中身を同一視し、再帰的な構造を作るためのパターン。木によく使われる。というか改めてCompositeパターンと言われる以前から当然のように使い倒している。
12.Decorator

オブジェクトに修飾(加工)を何度も施していくためのパターン。再帰構造を表現するのが目的のCompositeとは異なり中心の具象クラスに機能を追加していくことが目的。
思いつくところではHTTPサーバインスタンスにクッキー認証などのミドルウェアをかぶせていく利用先があるか。
メリット
- 飾り枠と中身が同一視されているため、APIが全て透過的に取り扱える(Decoratorでラップしても同じメソッドを呼び出せる)
- 中身を変更せずに機能追加ができる
- 動的に機能が追加できる
構造を渡り歩く
13.Visitor

データ構造と処理を分離し、構造を渡り歩く訪問者クラスに処理を任せるためのパターン。データ構造側ではacceptメソッドを実装して訪問者を受け入れる。
ConcreteVisitorはConcreteElementとは別に独立して開発できる。デザインパターン全体の目的として、Open-Closed Principle、拡張に対しては開かれており、修正に対しては閉じられているような部品としての再利用性が高いクラスを目指しており、Visitorもその一つ。
14.Chain of Responsibility

決定する処理を行うクラスをたらい回しで決定し、処理を要求する側と処理する側を分離するためのパターン。
複数のオブジェクトを連結リストで保持し、リンクを渡り歩きながら適切なオブジェクト上で処理が実行される。
処理は一つの分岐で処理先を決定するよりも遅くなるが、プログラムが設計しやすくなることとのトレードオフと言える。
シンプルにする
15.Facade
(Facadeクラスが複数のクラスを参照して処理を行うだけなのでUMLクラス図は省略)
複雑な処理をまとめて高レベルのAPIを作り、単一の窓口を提供するためのパターン。
このパターンがやっていることは単純で、要はユーザコードの手前に一つレイヤを挟み、ユーザコードから分かりやすく使えるAPIを提供するだけ。自分の分野でいえば圧縮接尾辞配列と木のBP表現とLCP配列をまとめて圧縮接尾辞木の機能を提供するクラスがFacadeに相当するだろう。 私の実装したbr-index( https://github.com/U-Ar/br-index )もFacadeパターンと言えるといえば言える。
16.Mediator

多数のオブジェクトの動作を強調する必要があるとき、調停者(mediator)役と各オブジェクト間の通信のみ許すことで単純化するためのパターン。一方向にコントロールするFacadeと違って双方向の通信を行う。
GUIプログラミングにおける表示のコントロールロジックなどに使い道がある。(表示制御はmediator内でのみ取り扱う)
注意点
- 通信経路の組み合わせ爆発を抑える効果がある(インスタンス数に対して線形で済む)
- ConcreteMediator役はアプリケーション依存性の高い部分を詰め込むため再利用しづらい
状態を管理する
17.Observer

観察対象の状態変化を観察者に通知するためのパターン。観察対象の側から通知用のメソッドを呼び出すため、ObserverというよりNotify-Subscribeの関係といった方が直感的。
18.Memento

クラスのカプセル化を破壊することなく状態履歴の保存と復元を行うためのパターン。
全履歴を管理できるかと思って期待したが、インスタンスの数までしか無理そう。
Memento=記念品。状態のスナップショットを記念品と比喩
19.State

状態をクラスで表現するためのパターン。
Stateインタフェースで宣言するメソッドは、状態に依存して変化する処理。本来はクラスメソッド内で状態に応じてifで処理を分岐するが、それをクラス分割の段階で行っている。
注意点
- 処理の記述漏れが実行段階(if文)より前のコンパイル段階(クラスメソッドの実装)で分かる。
- 状態遷移を管理するクラスをどれにするかには注意。
- ConcreteStateが他のConcreteStateへの遷移を管理する形式だと、他の状態に遷移する条件が1つのクラスにまとまっていて分かりやすいが、他ConcreteStateへの依存性が生じてしまう。
- Context役が担当する場合、Mediator的な管理ができるが、Contextが全ConcreteStateを知らなければならない。
- 状態遷移をテーブルを利用して有限状態機械的に表現することもできる。
20.Flyweight

普通に扱うとメモリ消費や構築時間が大きいインスタンスをできるだけ共有して、無駄にnewしないためのパターン。
Flyweight=ボクシングのフライ級。プログラムを軽量化する意図を表している
注意点
21.Proxy
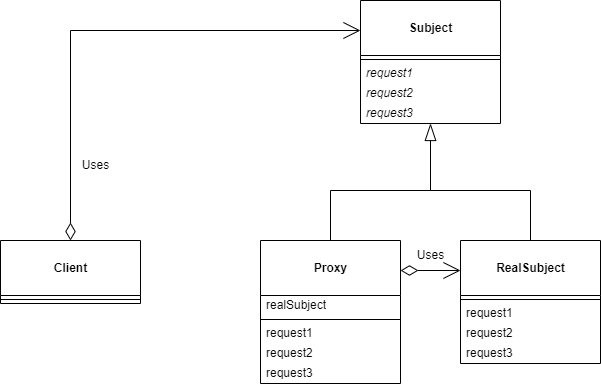
遅延評価を行い、必要なタイミングで初めてインスタンス生成を行うためのパターン。
遅延評価を行う/行わないクラスを個別に作ることで部品化が進み、また利用時の選択も明確に行える。
22.Command

一つの命令(Command)あるいはイベントを、命令を表すクラスのインスタンスとして表現するためのパターン。
23.Interpreter

文法規則をクラスで表現し、DSLのインタプリタを書くためのパターン。
本書の演習問題は全部解いたが、Interpreterの改良問題は特に歯ごたえがあった。( design_pattern/10_ExpressByClass/23_Interpreter_ex at main · U-Ar/design_pattern · GitHub )
総括
JavaではGCにより参照の取り扱いが単純であることから、パターンの本質に集中しやすかった。C++だとunique_ptrを間に挟む必要があったりして煩雑かつ読みづらいコードになる。
今までは古い印象もあってJavaを敬遠していたが、書いているととことんオブジェクト指向原理主義という方針が一貫したある意味純粋な言語で、それゆえに洗練されていてむしろ新しい印象へと改まった。
C++のような「すべてを包含していてどんな書き方もできる言語」よりも、書き方のパターンを原則に従って指示してくるJavaのような言語の方が好みかもしれない。標準ライブラリが極めて充実しており、これ標準装備されてないかなと思ってタイプしてみたメソッドが大抵存在していることも高評価ポイント。